Генератор речи
Этот модуль заставляет micro:bit говорить, петь и издавать другие звуки, похожие на речь.
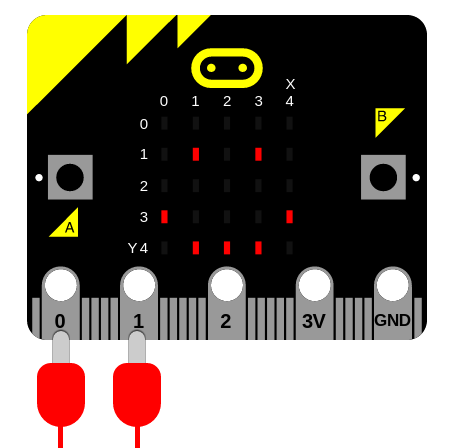
built-in speaker V2. Вы можете подключить проводные наушники или динамик к контакту 0 и GND на краевом разъеме, чтобы слышать звук:
Примечание
Эта работа основана на удивительных усилиях по обратному инжинирингу Себастьян Маке на основе старой программы преобразования текста в речь (TTS) под названием SAM. (программное обеспечение Automated Mouth), первоначально выпущенное в 1982 г. Commodore 64. Результатом стала небольшая библиотека C, которую разработчики приняли и адаптирован для micro:bit. Вы можете узнать больше из his homepage. Много информации в этом документе была получено от первоначального руководства, которое можно найти here.
Синтезатор речи может воспроизводить звук продолжительностью около 2,5 секунд от 0 до 255 символов текстового ввода.
Для доступа к этому модулю вам необходимо:
import speech
Функции
- speech.translate(words)
Данные английские слова в строке
words, вернуть строку, содержащую лучшее предположение о подходящих фонемах для произнесения. Выход генерируется с использованием библиотеки https://github.com/s-macke/SAM/wiki/Text-to-phoneme-translation-table.Эту функцию следует использовать для генерации первого приближения фонем, которые могут быть дополнительно отредактированы вручную для улучшения точности, интонации и акцент.
- speech.pronounce(phonemes, \*, pitch=64, speed=72, mouth=128, throat=128)
- speech.pronounce(phonemes, \*, pitch=64, speed=72, mouth=128, throat=128, pin=pin0)
Произнесите фонемы в строке
phonemes. Подробнее смотреть ниже как использовать фонемы для точного управления выходным сигналом синтезатора речи. Переопределите дополнительные настройки высоты тона, скорости, рта и горла, чтобы изменить тембр (качество) голоса.
- speech.say(words, \*, pitch=64, speed=72, mouth=128, throat=128)
- speech.say(words, \*, pitch=64, speed=72, mouth=128, throat=128, pin=pin0)
Произнесите английские слова в строке
words.
- speech.sing(phonemes, \*, pitch=64, speed=72, mouth=128, throat=128)
- speech.sing(phonemes, \*, pitch=64, speed=72, mouth=128, throat=128, pin=pin0)
Пропойте фонемы, содержащиеся в строке
phonemes. Изменение высоты тона и продолжительность ноты описана далее. Переопределите необязательный шаг, настройки скорости, рта и горла, чтобы изменить тембр (качество) голос.
Пунктуация
Пунктуация используется для изменения подачи речи. Синтезатор понимает четыре знака препинания: дефис, запятую, точку и вопросительный знак.
Дефис (-) вставляет короткую паузу в речи.
Запятая (,) отмечает границу фразы и вставляет паузу примерно
вдвое больше дефиса.
Точка (.) и вопросительный знак (?) обозначает конец предложения.
Точка вставляет паузу и заставляет высоту тона падать.
Тембр
Тембр звука – это качество звука. Это разница между
голос робота и голосом человека. Чтобы контролировать
тембр меняйте числовые настройки pitch, speed, mouth и
throat.
Высота тона и скорость настройки достаточно очевидны и в основном сводятся к следующемим категориям:
Pitch:
0-20 непрактичный
20-30 очень высоко
30-40 высокий
40-50 высокий нормальный
50-70 нормальный
70-80 низкий нормальный
80-90 низкий
90-255 очень низко
(По умолчанию 64)
Скорость:
0-20 непрактичный
20-40 очень быстро
40-60 быстрый
60-70 быстрый разговорный
70-75 нормальный разговорный
75-90 повествование
90-100 медленный
100-225 очень медленный
(По умолчанию 72)
Значения рта и горла немного сложнее объяснить, и следующие описания основаны на наших слуховых впечатлениях от речи, значение каждой настройки можно изменять.
Для начала вот несколько примеров:
speech.say("I am a little robot", speed=92, pitch=60, throat=190, mouth=190)
speech.say("I am an elf", speed=72, pitch=64, throat=110, mouth=160)
speech.say("I am a news presenter", speed=82, pitch=72, throat=110, mouth=105)
speech.say("I am an old lady", speed=82, pitch=32, throat=145, mouth=145)
speech.say("I am E.T.", speed=100, pitch=64, throat=150, mouth=200)
speech.say("I am a DALEK - EXTERMINATE", speed=120, pitch=100, throat=100, mouth=200)
Фонемы
say функция позволяет легко произносить речь, но часто это не точное.
Чтобы убедиться, что синтезатор речи произносит вещи
правильно как хотите, нужно использовать фонемы: самые маленькие
воспринимаемые единицы звука, которые можно использовать для различения различных
слова.
pronounce функция принимает строку, содержащую упрощенную и читаемую
версию International Phonetic Alphabet
и необязательные аннотации для указания интонация и ударение.
Преимущество использования фонем в том, что вам не нужно знать, как правильно писать! Скорее, вам нужно только знать, как сказать слово, чтобы написать его по буквам. фонетически.
В таблице ниже перечислены фонемы, понятные синтезатору.
Примечание
Таблица содержит фонему в виде символов и пример слова. То слова-примеры имеют звук фонемы (в скобках), но не обязательно одинаковые буквы
ПРОСТЫЕ ГЛАСНЫЕ ЗВОНКОВЫЕ СОГЛАСНЫЕ IY f(ee)t R (r)ed IH p(i)n L a(ll)ow EH b(e)g W a(w)ay AE S(a)m W (wh)ale AA p(o)t Y (y)ou AH b(u)dget M Sa(m) AO t(al)k N ma(n) OH c(o)ne NX so(ng) UH b(oo)k B (b)ad UX l(oo)t D (d)og ER b(ir)d G a(g)ain AX gall(o)n J (j)u(dg)e IX dig(i)t Z (z)oo ZH plea(s)ure ДИФТОНГИ V se(v)en EY m(a)de DH (th)en AY h(igh) OY b(oy) AW h(ow) OW sl(ow) UW cr(ew)
ГЛУХИЕ СОГЛАСНЫЕ S (S)am SH fi(sh) F (f)ish TH (th)in P (p)oke T (t)alk K (c)ake CH spee(ch) /H a(h)ead
СПЕЦИАЛЬНЫЕ ФОНЕМЫ UL sett(le) (=AXL) UM astron(om)y (=AXM) UN functi(on) (=AXN) Q kitt-en (glottal stop)
Пользователю также доступны следующие нестандартные символы:
YX окончание дифтонга (weaker version of Y)
WX diphthong ending (weaker version of W)
RX R после гласной (smooth version of R)
LX L после гласной (smooth version of L)
/X H перед гласной или согласной не переднего ряда - как в (wh)o
DX T как в pi(t)y (weaker version of T)
Вот некоторые редко используемые комбинации фонем (и предлагаемые альтернативы):
ФОНЕМА НАВЕРНОЕ ВЫ ХОТИТЕ: ЕСЛИ ЭТО НЕ РАЗДЕЛЯЕТ СЛОГИ, КАК:
КОМБИНАЦИЯ
GS GZ e.g. ba(gs) bu(gs)pray
BS BZ e.g. slo(bz) o(bsc)ene
DS DZ e.g. su(ds) Hu(ds)son
PZ PS e.g. sla(ps) -----
TZ TS e.g. cur(ts)y -----
KZ KS e.g. fi(x) -----
NG NXG e.g. singing i(ng)rate
NK NXK e.g. bank Su(nk)ist
Если Вы используете что-либо кроме фонем, описанных выше, ValueError
будет возбуждено исключение. Передайте фонемы в виде такой строки:
speech.pronounce("/HEHLOW") # "Hello"
Фонемы делятся на две большие группы: гласные и согласные.
Ниже описнные правила относятся к английскому языку
Гласные далее подразделяются на простые гласные и дифтонги. Простые гласные не меняют звучание, когда вы их произносите, тогда как дифтонги начинаются с единицы звучат и заканчиваются другим. Например, когда вы произносите слово «масло», «ой» гласная начинается со звука «о», но меняется на звук «и».
Согласные также подразделяются на две группы: звонкие и глухие. Озвученный согласные требуют, чтобы говорящий использовал свои голосовые связки для воспроизведения звука. Например, такие согласные, как «Л», «Н» и «З», звонкие. Глухие согласные производятся потоком воздуха, например «P», «T» и «SH».
Как только вы привыкнете к этому, система фонем станет легкой. Для начала немного написание может показаться сложным (например, в слове «приключение» есть буква «СН»), но Правило состоит в том, чтобы писать то, что вы говорите, а не то, что пишете. Эксперименты лучше всего способ разрешения проблемных слов.
Также важно, чтобы речь звучала естественно и понятно. Помогать с улучшением качества разговорного вывода часто полезно использовать встроенный система ударения для добавления интонации или ударения.
Имеется восемь маркеров стресса, обозначенных цифрами от 1 до 8. Просто вставьте необходимое число после ударной гласной. Например, отсутствие выражения «/HEHLOW» значительно улучшается (и дружелюбнее), когда написано «/HEH3LOW».
Также возможно изменить значение слов через то, как они подчеркнул. Рассмотрим фразу «Почему я должен идти в магазин пешком?». Возможно произносится по-разному:
# Вам нужна причина, чтобы сделать это.
speech.pronounce("WAY2 SHUH7D AY WAO5K TUX DHAH STOH5R.")
# Вы не хотите идти.
speech.pronounce("WAY7 SHUH2D AY WAO7K TUX DHAH STOH5R.")
# Вы хотите, чтобы это сделал кто-то другой.
speech.pronounce("WAY5 SHUH7D AY2 WAO7K TUX DHAH STOHR.")
# Вы бы предпочли водить.
speech.pronounce("WAY5 SHUHD AY7 WAO2K TUX7 DHAH STOHR.")
# Вы хотите пойти куда-нибудь еще.
speech.pronounce("WAY5 SHUHD AY WAO5K TUX DHAH STOH2OH7R.")
Проще говоря, разные ударения в речи создают более выразительный тон речи. голос.
Они работают, повышая или понижая высоту тона и удлиняя соответствующую гласную. звук в зависимости от числа, которое вы даете:
очень эмоциональный стресс
очень сильное ударение
довольно сильный стресс
обычный стресс
жесткий стресс
нейтральное (без изменения высоты тона) напряжение
сбрасывающее напряжение
экстремальное напряжение сбрасывания высоты тона
Чем меньше число, тем более экстремальным будет акцент. Однако такие маркеры ударения помогут правильно произносить сложные слова. Например, если слог произносится недостаточно, поставьте маркер нейтрального ударения.
Также можно удлинять слова с помощью маркеров ударения.:
speech.pronounce("/HEH5EH4EH3EH2EH2EH3EH4EH5EHLP.”)
Пение
Можно заставить MicroPython петь фонемы.
Это делается путем аннотирования числа, связанного с высотой тона, к фонеме. Чем ниже число, тем выше тон. Числа примерно переводятся в музыкальные ноты как показано на схеме ниже:

Аннотации работают, предваряя знак решетки (#) и номер шага
перед фонемой. Шаг останется прежним, пока не появится новая аннотация.
Например, заставьте MicroPython петь вот такую гамму:
solfa = [
"#115DOWWWWWW", # Doh
"#103REYYYYYY", # Re
"#94MIYYYYYY", # Mi
"#88FAOAOAOAOR", # Fa
"#78SOHWWWWW", # Soh
"#70LAOAOAOAOR", # La
"#62TIYYYYYY", # Ti
"#58DOWWWWWW", # Doh
]
song = ''.join(solfa)
speech.sing(song, speed=100)
Для того, чтобы спеть ноту на определенную продолжительность, удлините повторяя гласные или звонкие согласные фонемы (как показано в пример выше).
Экспериментирование, внимательное слушание и корректировка — единственный верный способ работать.
Как это работает?
В оригинальном мануале все понятно:
Во-первых, вместо того, чтобы записывать фактическую форму речевого сигнала, мы сохраняем только частотные спектры. Делая это, мы экономим память и подбираем другие преимущества. Во-вторых, мы […] храним некоторые данные о времени. Эти числа, относящиеся к длительности каждой фонемы при разных обстоятельствах, а также некоторые данные о времени перехода, чтобы мы могли знать, как смешать фонему с ее соседями. В-третьих, мы разрабатываем систему правил иметь дело со всеми этими данными, и, к нашему большому удивлению, наш компьютер болтать в кратчайшие сроки.
—S.A.M. owner’s manual.
Выходные данные передаются через функции, предоставляемые модулем «аудио» и, привет, вуаля, у нас есть говорящий микро:бит.
Примеры
"""
speech.py
~~~~~~~~
Simple speech example to make the micro:bit say, pronounce and sing
something. This example requires a speaker/buzzer/headphones connected
to P0 and GND,or the latest micro:bit device with built-in speaker.
"""
import speech
from microbit import sleep
# The say method attempts to convert English into phonemes.
speech.say("I can sing!")
sleep(1000)
speech.say("Listen to me!")
sleep(1000)
# Clearing the throat requires the use of phonemes. Changing
# the pitch and speed also helps create the right effect.
speech.pronounce("AEAE/HAEMM", pitch=200, speed=100) # Ahem
sleep(1000)
# Singing requires a phoneme with an annotated pitch for each syllable.
solfa = [
"#115DOWWWWWW", # Doh
"#103REYYYYYY", # Re
"#94MIYYYYYY", # Mi
"#88FAOAOAOAOR", # Fa
"#78SOHWWWWW", # Soh
"#70LAOAOAOAOR", # La
"#62TIYYYYYY", # Ti
"#58DOWWWWWW", # Doh
]
# Sing the scale ascending in pitch.
song = ''.join(solfa)
speech.sing(song, speed=100)
# Reverse the list of syllables.
solfa.reverse()
song = ''.join(solfa)
# Sing the scale descending in pitch.
speech.sing(song, speed=100)